张岩,2023-06-13
个人简介:张岩教授于1995年7月加入北京大学智能学院(前身是:北京大学信息科学中心、北京大学智能科学系),1992、1995和2002年在北京大学计算机科学与技术系(现为北京大学计算机学院)分别获得理学学士、理学硕士和理学博士学位。张岩教授曾于1996年9月至1997年1月访问香港中文大学计算机科学与工程系,2004年8月至2005年8月访问伊利诺伊大学厄巴纳-香槟分校计算机科学系。 张岩教授的研究兴趣是智能信息检索、自然语言处理和大数据分析,近年来在这些领域的国际期刊和会议上发表论文100多篇,指导的论文曾获WSDM最佳论文荣誉奖、JCDL最佳学生论文提名奖、AIRS最佳Poster奖,合作的论文曾入选“第二届中国科协优秀科技论文”、“中国知网学术精要高PCSI论文”。他的研究小组被命名为DAIR(数据分析和智能检索)。本文为张岩教授在全球数字金融中心(杭州)举行“人工智能与数字金融”研讨会发言。
开篇
很多时候,人类对世界和复杂事物的认识过程就是一种类似“盲人摸象”的情境,以下的内容分享也是这样。其中的不当之处,欢迎大家指出。
ChatGPT的成功
去年底的时候,OpenAI开发的ChatGPT横空出世,取得了惊人效果,成为AI的一个爆品。ChatGPT原本功能就是一个大型的聊天工具,出来之后大家发现它不仅聊天聊得好,还可以干其他一些事情,干得居然还不错,比如说文案、翻译、编代码、帮写论文、写脚本等等,于是引起了轰动,取得了很惊艳的效果。
ChatGPT问世之后各种大模型纷纷登台亮相,有国际上的,也有国内的,这些大模型各有千秋。相比这些大模型的成功,我们其实更关心的是大数据的成功,因为我本人是研究大数据的,也有十几年了。数据应用集聚到一定程度,我们欣喜地看到终于导致质变,使得大模型具备了涌现能力。
涌现能力及可能的原因
什么是涌现能力?涌现能力是说大模型的参数量和数据应用规模未能达到某个阈值的时候,模型基本上不太具备解决某类任务的能力,但是当模型规模达到一定程度,同时使用的数据规模也跨过某个阈值的时候,模型对这类任务的解决效果就呈现出突然的爆发式增长。
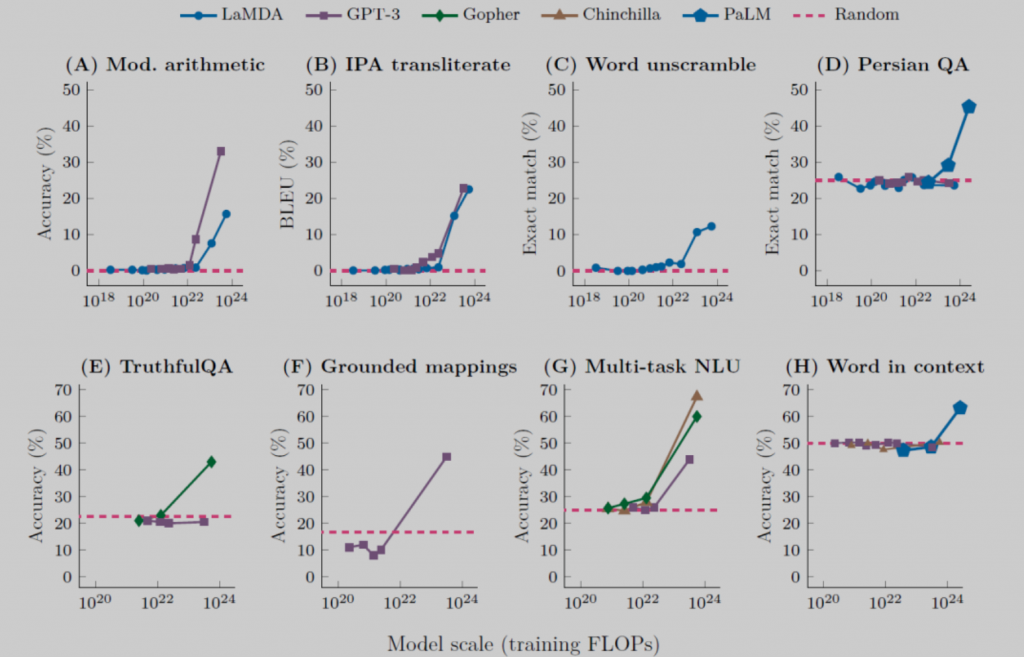
从这张图可以看出,像LaMDA、GPT-3、PaLM等大模型,它们在一些典型的任务上都具备涌现能力。
我们看一下GPT家族涌现能力的发展。Open AI在2018年的时候就推出了GPT-1,2019年发布了GPT-2,但是GPT-1、GPT-2都没有引起太多的轰动,甚至有些人都没有太听说过。直到2020年5月发布GPT-3模型,参数量达到了很惊人的175B,开始引起关注。后来GPT-3.5又在GPT-3的基础上得到进一步改良,而ChatGPT基于GPT3.5做了进一步优化,比如使用了来自于人类的强化学习方法等等。ChatGPT参数量保持了175B,就是GPT-3、GPT-3.5、ChatGPT,乃至GPT-4,基本上模型规模没有太大的变化。除了模型参数量巨大,ChatGPT还使用了大量的预训练数据,预训练数据达到45TB。45TB听着好像不是很大,但这都是文本数据,45TB的文本数据其实是非常大的规模。有了巨量参数和海量预训练数据的加持,ChatGPT终于展现出惊人的涌现能力。
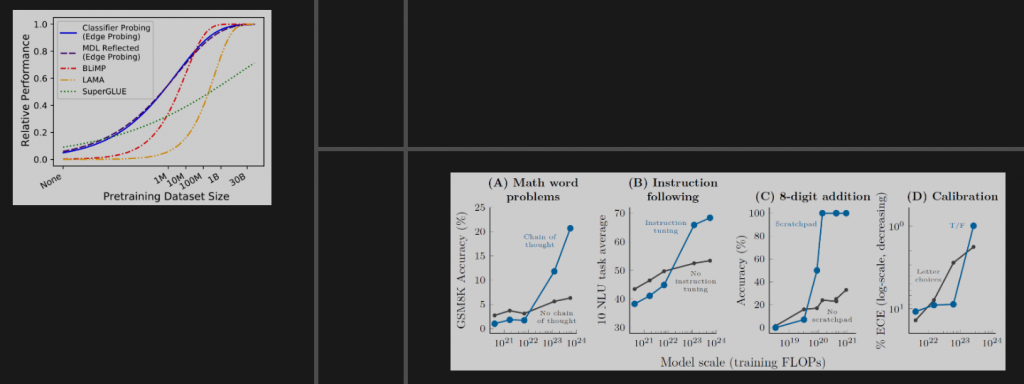
我们看到涌现能力是一种规模效应,这种规模效应不仅依赖于某模型本身,也依赖于训练数据和训练过程。像上面的左图,预训练数据集到了一定规模之后,性能呈现突然式的增长。右边几个关于训练过程的图也是这样,有时候会更明显一些。所以说当模型和数据都跨过了门槛,并且经过了充分的训练才能出现规模效应,从而产生令人吃惊的能力和海量的知识。
从大数据到海量知识
谈到知识我们就有一个问题,大模型它是如何存储知识的?我们说大语言模型从海量数据中学习到的知识可以粗略地分为两大类:一类是语言类知识,一类是世界知识。现在的大语言模型基本上都是应用Google公司的Transformer架构模式。对于语言类知识,浅层的语言类知识比如词性、语法、句法等等,存储在Transformer的底层和中层;抽象的语言类知识,比如说语义知识存储在Transformer的中层和高层。大模型从训练数据中获得的世界知识,比如人类常识等(黄河长江是中国的两条河流这类知识),主要分布在Transformer的中层和高层,尤其聚集在中层。随着Transformer模型层深的增加,参数量呈指数增长,大模型能够学习到的知识量也是以指数级增加。概念上,我们完全可以把大模型看作是一种以模型参数体现的隐式知识图谱。
观念之争
说到重要的知识,其如何获得,这便存在着观念之争。有人认为只有大数据才能产生大知识,有人认为不一定,小样本也可以产生大知识。
我们说这要看具体谈论的场景。如果一切从零开始,我们前面已经论述了,大模型必须有足量大数据的支持才能突破限制,展示涌现能力,产生大知识。有人就说了,人类学习可不是这样的,人类学习的时候不是可以小样本嘛,通过小样本学习就能获得重要知识。我们这里有个解释:人类的这种小样本学习实际上是因为前面已经有N代学习产生的知识和技能,已经固化在DNA等遗传物质上了,这样进行知识积累的预训练过程,必须靠大数据的支持。具体到某个人的学习,也就是看似从小样本获得知识的过程,基本上相当于大模型的prompt训练,连fine tune都说不上。
两个理念
有了前面的这些认识之后,我们慢慢形成这样一个理念:当前是数据在驱动人工智能的发展,大数据产生海量知识。我们只要将足够的数据交给大模型,只要知道这些数据之间的关联关系,大模型的深度学习算法就可以帮助模型发现过去所不能发现的新模式、新知识、新规律。
曾担任Google公司研究部主任的彼得·诺维格说过,所有的模型都是错误的,进一步说,没有模型你也可以成功。这话听着是有点过头,但是我们的确认为,模型虽然是非常重要的,然而在AI的发展中,至少在目前的发展阶段,数据比模型更为重要。
大家知道当前的AI的模式就是模型加数据加算力加时间(AI=模型+数据+算力+时间),时间关系我就不再详细解释了。可以看到大模型的参数是海量的,大模型使用的预训练数据也是非常多的,但海量参数和巨量的预训练数据,两者匹配吗?这是一个非常重要的问题。实际上有研究表明当前的神经网络模型,其参数足以记忆全部的训练数据;而有研究进一步表明,当前的深度学习模型往往是参数规模太大了,庞大到浪费的程度。相对于这些过度参数化的模型的规模,其训练数据–如果我们谈论的是来自物理世界、现实世界的那些训练数据–那是远远不够的;即使是用到了机器随机生成的训练数据,这些训练数据和这些大规模的参数量相比仍然是稀缺的。
但我们也不必担心。虽然大模型的参数规模大到了浪费的程度,但是大模型也表现出来它很聪明的一面,那就是它具有简约的特质。我们前面已经说过了,目前的大语言模型基本上都是架构在Google的Transformer结构上的,而Transformer即使没有明确的设计,它一般也只使用参数的一小部分来解析给定的输入,所以Transformer可以被视为简约模型。另外,有相当多的大模型都使用了sparse结构。Sparse模型一般参数量巨大,但对于具体的训练实例,模型往往会通过它的路由机制只使用参数中的一小部分,使得参与训练和推理的活跃参数量比较小,所以计算量不会太大,计算速度还是很快的。Sparse模型预计会成为未来大模型发展的主流。
于是我们就形成第二个理念:相比天量的参数,大模型预训练中所用到的数据量其实还是远远不够的。这也解释了为什么Alpaca、Vicuna这些被称为小羊驼的模型为何能够成功。就是因为参数量过度了,完全可以使用一些方法把参数量压缩,使得模型在特定场景应用中仍然能够发挥其性能。至于fine-tuning和prompting其实做的是场景适应性训练,加强相关参数的唤醒和使用。
发展数据工程
认识到数据的重要性,就要大力发展数据工程。发展数据工程的时候,要考虑数据的两个要素:数量和质量。这两个要素中,当然是质量优先,但质量达到一定程度即可,不必过于追求。数据质量可以说就是数据反映物理世界的能力,它包含了数据的信息含量以及数据多样性等多个衡量标准。高质量的数据是非常重要的,比如Wiki,它就是世界知识密度极高的高质量数据,它的应用对于这个大语言模型中的成功来讲是不可或缺的。另外还可以增加数据多样性,数据多样性的增加也是激发大语言模型新能力的一个很有效的手段。
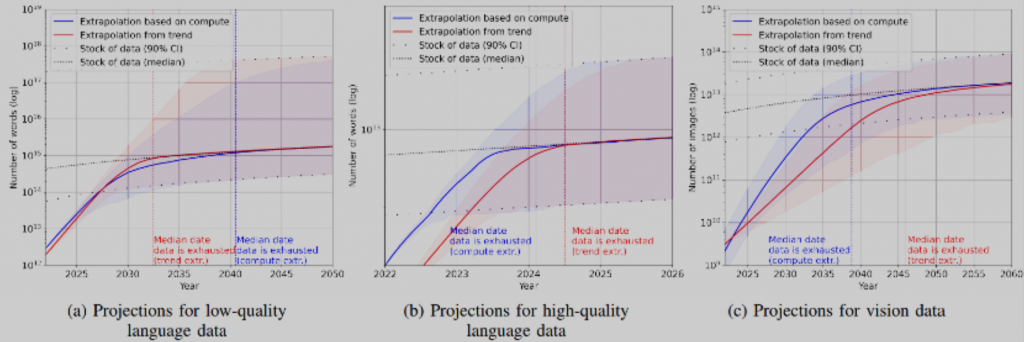
我们强调数据的重要性,强调要大量使用数据,但是数据用下去会不会总有一天会用完呢?关于这个问题,Pablo Villalobos等人在“Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning”这篇论文中进行了估算。根据他们的估算,如果以目前的趋势用下去,高质量的语言数据在2026年就将被用完,低质量的语言数据在2030年到2050年之间的某个阶段会被用完,而视觉数据会在2030年到2060年中的某个阶段被用完。当然,这只是他们的估算,我们和另外一些人对此是乐观的。我们认为在数据使用过程中,人们还会源源不断地发现新的数据源,同时在使用过程中还会不断提高大模型对数据的应用效率,因此不用太过担心数据用完的问题。
既然不用担心,那就可以放心使用数据了。Open AI的研究表明,独立增加预训练的数据量,或者是增大模型参数规模,或者是延长模型训练时间,模型效果都会越来越好。
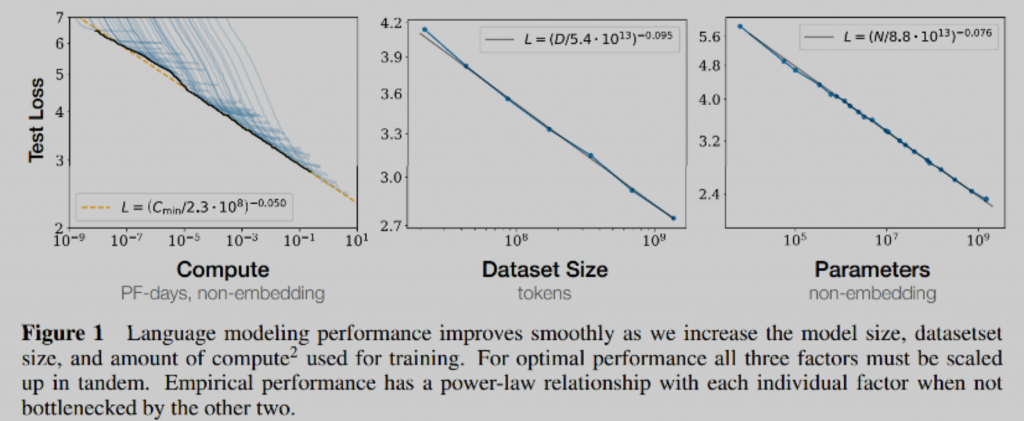
这样对于数据的应用我们就有两种策略。一种策略是增加训练数据量,模型参数量保持不变,适当增加训练步数,这样会充分发挥参数的作用,提高模型效果。另外一种策略是增加训练数据量,同比例减少模型参数,并适当增加训练的步数,这样可以在不降低模型效果的前提下,极大地缩小模型规模。缩小模型规模是一件非常好的事情,会给我们带来很多好处,比如说在应用的时候速度会非常快,会更加节能、低碳环保等等。
谈到对新数据的使用,大模型的确处于一个看起来是两难的境地:如果不进行重新的预训练,大模型就没有办法把最新信息充分纳入到模型中,但是动辄进行预训练,其代价非常巨大。一个变通的方法是把大模型和搜索相结合。有人称作LLM-powered Search,有人觉得不合适,应该叫Search-powered LLM。这个无所谓,重要的是如何把大语言模型和搜索进行更为密切的有机结合。一个简单的方法,就是它们之间可以多迭代几次。
关于AIGC
前面我们主要探讨了大模型对于数据的应用,下面有必要稍微说一下大模型产出的数据的问题,比如说AIGC。谈到AIGC,现在大家形成一个共识,那就是AIGC内容必须进行适当的评价和监管,否则将是一件很可怕的事情,最终会失控。目前大家也在提各种方案,比如说让大型自己去评价自己产生的内容,或者让多个大模型之间互相评价,以及使用传统的方式进行评价和过滤等等。在此我的一个观点是,首先我非常同意对大模型的输出进行监管,但不太赞成对大模型的训练数据过于苛刻。主要原因有两点。一个在前面已经说过,如果没有足量的训练数据,大模型就很难继续进步。另外就是,即使对训练数据进行控制,大模型的输出也很可能超出想象。如果大模型输出的一切都在控制范围之内,不会超出大家的想象,那不是我们想要的大模型,是令人失望的大模型。
未来AIGC的产生会越来越容易,应用也会越来越广泛,所以我们感到有必要对AIGC进行标识,否则可能会混淆人类的知识体系,乃至颠覆人类的认知。为了更好地标识AIGC,需要对其进行辨别、追踪和溯源。(1)一些AI产生的数据与来自物理世界的数据是可以辨别的,需要研究一些辨识方法。(2)另外一些AI产生的数据与来自物理世界的数据可能很难辨别,或者从理论上就无法辨别,那么这些AIGC只能依赖生产者的主动标识,且这种标识应支持在传播过程中的追踪和溯源。在这里我们很高兴分享一个消息,本周一Google宣布将会在其工具框中加两个新工具,其中一个就是对Google自己的AI所产生的图片进行主动标识,并且这种标识可追踪可溯源。
两点思考
最后是两点思考,本来是想写成两点建议,但不知道向谁建议。没法建议的话,我自己思考一下总是可以的,所以就改成了两点思考。
AI的发展道路其实很曲折的,其发展和应用受限于技术、资本、法律,以及人类的价值观、道德观、伦理观等等。限制已经很多了,最好不要再人为设置更多限制了。有人可能问,你说AI有这么多限制,但是现在发展还是挺好的呀。这可能是我们认识有所不同,我个人认为AI到ChatGPT出来才算刚刚发展。套用一部电影中的两句词:目前AI的发展阶段,不是开始的结束,更不是结束的开始,只是开始的开始,刚刚萌芽而已。
另外一个思考是,数据要流动起来,数据只有流动起来才能发挥作用,才能产生价值,放在那里不用,无论如何也是一种浪费,无论你有再多的理由也是一种浪费。当然了,这个社会是各种力量的平衡,出于一些原因就是没法使用,那就只能不用。浪费就浪费吧,人类浪费的东西多了,也不在乎浪费更多。
致谢
感谢参考文献的所有作者,感谢文中所用网上资源的提供者和所有者。致谢北京大学智能学院“数据智能与计算智能中心”以及北京大学智能学院“DAIR研究组”。
主要参考文献
[01] Samuel R. Bowman.Eight Things to Know about Large Language Models. https://cims.nyu.edu/~sbowman/eightthings.pdf
[02] Mor Geva et.al.Transformer Feed-Forward Layers Are Key-Value Memories. https://arxiv.org/pdf/2012.14913.pdf
[03] Jared Kaplan et.al.Scaling Laws for Neural Language Models. https://arxiv.org/pdf/2001.08361.pdf
[04] Zonglin Li et.al.Large Models are Parsimonious Learners: Activation Sparsity in Trained Transformers. https://arxiv.org/abs/2210.06313
[05] Kevin Meng et.al.Locating and Editing Factual Associations in GPT. https://arxiv.org/pdf/2202.05262.pdf
[06] Kevin Meng et.al.Mass-Editing Memory in a Transformer. https://arxiv.org/pdf/2210.07229.pdf
[07] Microsoft.The new Bing: Our approach to Responsible AI. https://blogs.microsoft.com/wp-content/uploads/prod/sites/5/2023/04/RAI-for-the-new-Bing-April-2023.pdf
[08] Aarohi Srivastava.Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models. https://arxiv.org/pdf/2206.04615.pdf
[09] Pablo Villalobos et. al.Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning. https://arxiv.org/pdf/2211.04325.pdf
[10] Jason Wei et.al.Emergent Abilities of Large Language Models. https://arxiv.org/pdf/2206.07682.pdf
[11] Jason Wei et.al.Inverse scaling can become U-shaped. https://arxiv.org/pdf/2211.02011.pdf
[12] Chiyuan Zhang et.al.Understanding deep learning requires rethinking generalization. Communications of the ACM, 64(3):107–115, 2021
[13] Yian Zhang et.al.When Do You Need Billions of Words of Pre-training Data? https://aclanthology.org/2021.acl-long.90.pdf
[14] Wayne Xin Zhao et.al.A Survey of Large Language Models. https://arxiv.org/pdf/2303.18223.pdf
[15] Chen Zhu et.al.Modifying Memories in Transformer Models. https://arxiv.org/pdf/2012.00363.pdf